最近仕事で自然言語処理を使ったモデルを作成していたんですが、 前処理やモデルを作る際に数分〜数十分単位の処理待ちの空き時間が頻繁に発生してしまい、 その度集中力が切れる問題に悩まされていました。
モデルの学習に時間がかかってしまうのはまた別の解決策を考えるとして、 今回は時間のかかる前処理をDaskをつかって高速化した方法をお話ししようと思います。
この記事は PyLadies Advent Calendar 2018 - Adventar の18日目の記事になります。
Daskとは?
Daskとは、numpyやpandasなどのデータを簡単に並列計算するライブラリ。
あまり公式のチュートリアルがわかりやすくない(気がする)ので、基本的な使い方は Python Dask で 並列 DataFrame 処理 - StatsFragments を見てみると良い。
サンプルデータ
今回はKaggleのToxic Comment Classification Challengeのデータを使ってテキストの前処理をしていく。
このコンテスト自体は、誹謗中傷などの6種の良くない表現が含まれているかどうかを当てるというもので、 約16万件の数百文字程度のテキストが入ったデータセットとなっている。
import pandas as pd df = pd.read_csv('input/train.csv',) print(f"{df.shape[0]:,d}行") df.head()
159,571行
| id | comment_text | toxic | |
|---|---|---|---|
| 0 | 0000997932d777bf | Explanation\nWhy the edits made under my usern... | 0 |
| 1 | 000103f0d9cfb60f | D'aww! He matches this background colour I'm s... | 0 |
| 2 | 000113f07ec002fd | Hey man, I'm really not trying to edit war. It... | 0 |
| 3 | 0001b41b1c6bb37e | "\nMore\nI can't make any real suggestions on ... | 0 |
| 4 | 0001d958c54c6e35 | You, sir, are my hero. Any chance you remember... | 0 |
通常の名詞抽出処理
今回はcomment_text列に対して、名詞のみを抜き出す前処理をすることを目的としていく。
nltkを使って、名詞を抜き出すような処理を定義する。
import nltk def get_nouns(sentence): tokenized = nltk.word_tokenize(sentence) nouns = [word for (word, pos) in nltk.pos_tag(tokenized) if pos[:2] == 'NN'] return nouns
comment_text列に対して上記関数を実行する。
df['comment_text'].head().apply(get_nouns)
0 [Explanation, edits, Hardcore, Metallica, Fan,...
1 [D'aww, colour, Thanks, talk, January, UTC]
2 [Hey, man, war, guy, information, edits, talk,...
3 [suggestions, improvement, section, statistics...
4 [hero, chance, page]
Name: comment_text, dtype: object
この処理を全データについてこの処理を実行すると11分かかった。
それほど長い時間ではないが、集中力が行方不明になるには十分な時間である。
Daskを使って処理
この名詞を抜き出す処理を、daskを使って書き換えてみよう。
Daskのインストールは pip install "dask[complete]" でできる。
まずはDataFrameをDaskオブジェクトに変換する。
import dask.dataframe as dd # Daskに変換(npartitions:分割数) ddf = dd.from_pandas(df, npartitions=10)
Daskオブジェクトに変換するには、npartitionsというオブジェクトを何分割して処理をするかを指定する引数を設定する必要がある。 基本的にはCPUのコア数までの好きな値を指定すれば良い。
CPUのコア数に設定する場合はいつも以下のように書いている。
import multiprocessing
ddf = dd.from_pandas(df, npartitions=multiprocessing.cpu_count())
ddf.divisionsをみてみると、DataFrameがどのindexで分割されているか確認することができる。
ddf.divisions
(0,
6649,
13298,
19947,
...)
実際に名詞抽出関数を適用するコードは以下になる。
# 1行だけ元のSeriesに関数を適用させ、metaデータを作成する meta = df['comment_text'].head(1).apply(get_nouns) # metaを引数で指定して、普通に関数をapplyする準備をする res = ddf['comment_text'].apply(get_nouns, meta=meta) # 実際にapplyを各partitionに分けて実行し、結合する。 rtn = res.compute(scheduler='processes')
metaというのは指定した関数の返り値の各列がどんな型なのかを指定する引数。
詳しくは Internal Design — Dask 1.0.0 documentation あたりに書いてある。
列と型を指定したり、返り値と同じ型のオブジェクトによって指定することができる。
個人的には、関数を普通に元のDataFrameやSeriesの1行に適用して返ってきたものを指定するのが一番指定が楽という結論に至っているので、1行目の様な処理を行っている。
2行目Daskオブジェクトのapply関数を呼んだ時点では、まだapplyは実行されていない。
実際に処理を実行するのは、3行目のapplyの返り値に対してcomputeを実行したときになる。
今回スケジューラはprocessesにしている。
デフォルトはスレッドになっているが、基本的にはプロセスを指定しておけば良い。
スケジューラについては Scheduling — Dask 1.0.0 documentation で詳細を確認できる。
print(rtn.head())
0 [Explanation, edits, Hardcore, Metallica, Fan,...
1 [D'aww, colour, Thanks, talk, January, UTC]
2 [Hey, man, war, guy, information, edits, talk,...
3 [suggestions, improvement, section, statistics...
4 [hero, chance, page]
Name: comment_text, dtype: object
無事Seriesに対するapplyと同じ結果が得られた。
コードとしては3行増えたくらいで難しくはない。
実行速度を24コアのマシンでpandas, dask(npartitions=4), dask(npartitions=8), dask(npartitions=24)で比較した結果が以下になる。
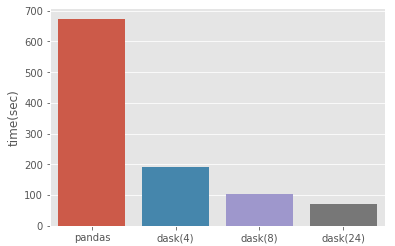
npartitions=8で計算したときに6倍くらい早くなっている。
これなら1分半くらいの待ち時間ですむ。ギリギリ集中力が迷子になる前に終わりそうだ。
map_partitionsを使って少し複雑な処理
もう少し複雑な処理をしてみる。
以下の3つのキーワードのセットを用意し、各テキストがこの単語の組み合わせのいずれかを含んでいるかを調べてみる。
キーワードは以下のように定義する。
keywords = pd.Series([
'you i', 'she i', 'he shit',
])
以下のようなマッチしたかを調べる関数を準備する。
import functools def is_match_keyword(keyword, text): target = set(text.lower().split(' ')) parts = set(keyword.split(' ')) # partsに含まれていて、targetに含まれていない単語がなければTrue return len(parts - target) == 0 def is_match_keywords(text_series, keyword_series): # 返り値となるSeriesを定義 rtn = pd.Series(0, index=text_series.index) # キーワード一つずつにマッチするか確認 for index, keyword in keyword_series.iteritems(): # まだresultが0の行に対してのみis_match_keywordをapplyしていく result.loc[rtn == 0] |= text_series.loc[rtn == 0].apply( functools.partial(is_match_keyword, keyword)) return rtn
先程と同じように、1行だけのデータに対して実行することで、meta情報を作成する、
meta = is_match_keywords(df['comment_text'].head(1), keyword_series=keywords)
今回はmap_partitionsという関数を使って計算してみる。
map_partitionsは分割したそれぞれのpartitionに対して普通にseries/dataframeが渡ってくるので、
関数内で普通にpandasのデータとして自由に扱える。
applyは複数列の情報を扱って処理するのには対応していないので、
複数列の情報を使った処理をしたい場合はmap_partitionsを使う。
# 実行する関数に引数を渡したい場合は、キーワード引数として渡す res = ddf['comment_text'].map_partitions(is_match_keywords, keyword_series=keywords, meta=meta) # 処理の実行 result = res.compute(scheduler='processes')
result.head()
0 False
1 False
2 False
3 True
4 False
dtype: bool
このような感じで、柔軟に普段pandasでしている処理を並列処理することができる。
個人的には、pandasで書いた処理をそのまま並列処理するにはmap_partitionsが使いやすいと思っている。
最後に
今回の記事のキーとなるのは以下の点です。
- Daskのapplyやmap_partitionsを使えばいろんな処理が簡単に並列処理できる
- Daskは返り値のmetaを指定しなければいけないけれど、1行だけ実行すると簡単にmeta情報を作れる
普段から処理を並列化することで、仕事の中の待ち時間を減らしていきましょう。
Daskに関する記事は調べてみるといくつかあるのですが、 簡単な計算処理をしているものが殆どで、実際に使うときの例が少ない印象だったので、今回の記事を書いてみました。
この記事でモデル作成中のみなさんの待ち時間を1分でも短くできたら嬉しいです :)